Scaling Instruction-Finetuned Language Models
擴充套件指令 - 微調語言模型
What's new?
有什麼新的?
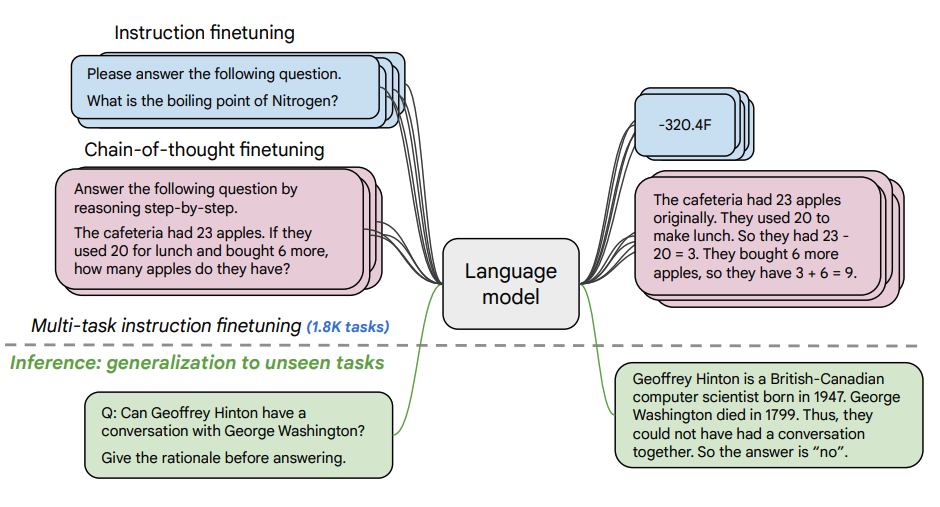
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
This paper explores the benefits scaling instruction finetuning (opens in a new tab) and how it improves performance on a variety of models (PaLM, T5), prompting setups (zero-shot, few-shot, CoT), and benchmarks (MMLU, TyDiQA). This is explored with the following aspects: scaling the number of tasks (1.8K tasks), scaling model size, and finetuning on chain-of-thought data (9 datasets used).
本文探討了擴充套件指令微調的好處,以及它如何提高各種模型(PaLM、T5)、提示設定(zero-shot、few-shot、CoT)和基準測試(MMLU、TyDiQA)的效能。這是透過以下方面進行探討的:擴充套件任務數量(1.8K個任務)、擴充套件模型大小,以及在思維鏈資料上進行微調(使用了9個數據集)。
Finetuning procedure:
Finetuning程式:
- 1.8K tasks were phrased as instructions and used to finetune the model
- Uses both with and without exemplars, and with and without CoT
- 1.8K個任務被表述為指令,用於微調模型
- 同時使用有和沒有範例,以及有和沒有CoT
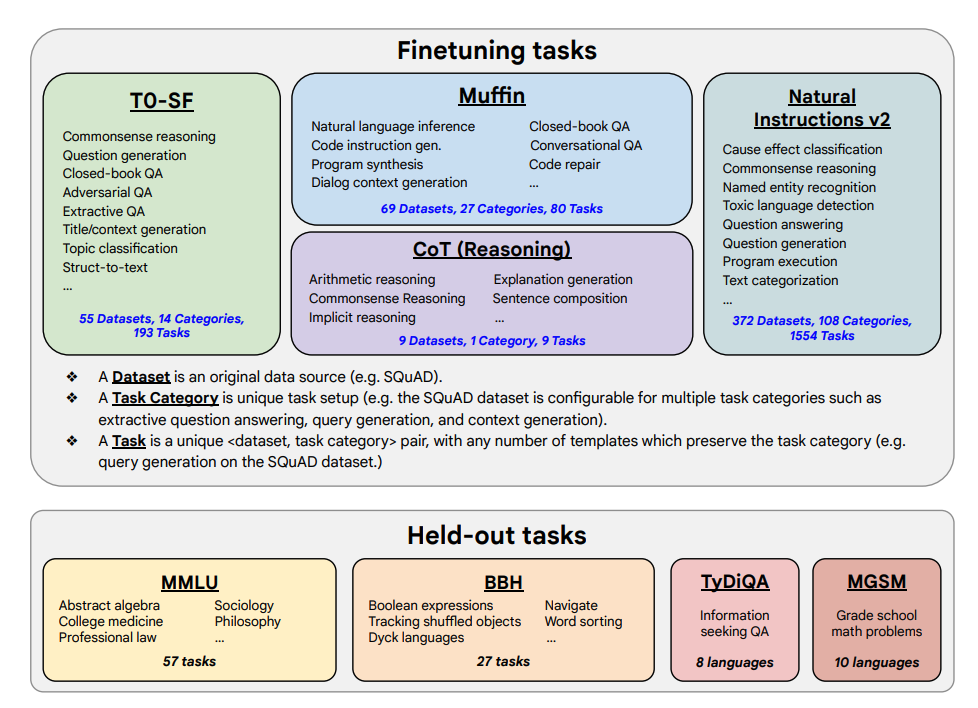
Finetuning tasks and held out tasks shown below:
Finetuning 任務和保留任務如下所示:
Capabilities & Key Results
能力和關鍵結果
- Instruction finetuning scales well with the number of tasks and the size of the model; this suggests the need for scaling number of tasks and size of model further
- Adding CoT datasets into the finetuning enables good performance on reasoning tasks
- Flan-PaLM has improved multilingual abilities; 14.9% improvement on one-shot TyDiQA; 8.1% improvement on arithmetic reasoning in under-represented languages
- Plan-PaLM also performs well on open-ended generation questions, which is a good indicator for improved usability
- Improves performance across responsible AI (RAI) benchmarks
- Flan-T5 instruction tuned models demonstrate strong few-shot capabilities and outperforms public checkpoint such as T5
- 指令微調隨著任務數量和模型大小的增加而擴充套件得很好;這表明需要進一步擴充套件任務數量和模型大小
- 將CoT資料集新增到微調中可以在推理任務上實現良好的效能
- Flan-PaLM具有改進的多語言能力;在一次性TyDiQA上提高了14.9%;在代表性不足的語言中進行算術推理的提高了8.1%
- Plan-PaLM在開放式產生問題上也表現良好,這是改進可用性的良好指標
- 提高了負責任的AI(RAI)基準的效能
- Flan-T5指令微調模型展示了強大的少樣本能力,並且優於T5等公共檢查點
The results when scaling number of finetuning tasks and model size: scaling both the size of the model and the number of finetuning tasks is expected to continue improving performance, although scaling the number of tasks has diminished returns.
當調整微調任務數量和模型大小時的結果: 預期同時調整模型大小和微調任務數量將繼續提高效能,但調整任務數量的效益會逐漸減少。
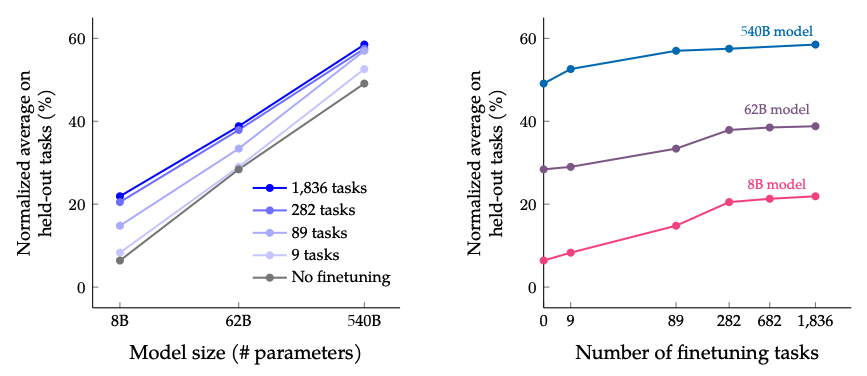
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
The results when finetuning with non-CoT and CoT data: Jointly finetuning on non-CoT and CoT data improves performance on both evaluations, compared to finetuning on just one or the other.
**使用非 CoT 和 CoT 資料進行微調的結果:**與僅在其中一個資料上進行微調相比,同時在非 CoT 和 CoT 資料上進行微調可以提高兩個評估的效能。
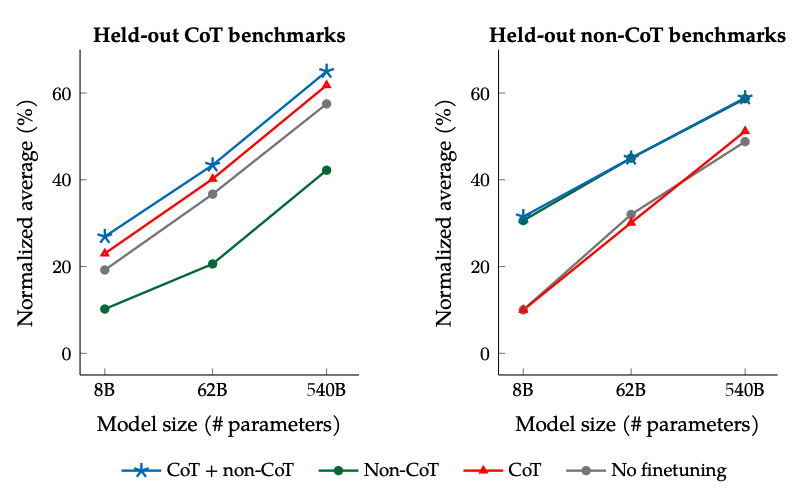
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
In addition, self-consistency combined with CoT achieves SoTA results on several benchmarks. CoT + self-consistency also significantly improves results on benchmarks involving math problems (e.g., MGSM, GSM8K).
此外,自我一致性結合CoT在多個基準測試中實現了SoTA結果。CoT + 自我一致性還顯著改善了涉及數學問題的基準測試結果(例如,MGSM,GSM8K)。
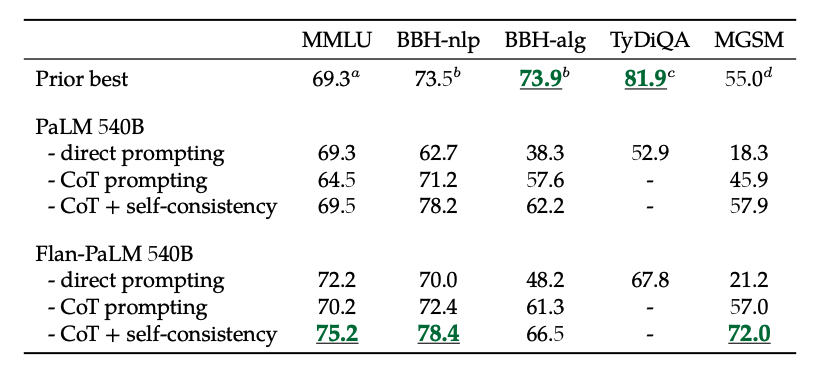
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
CoT finetuning unlocks zero-shot reasoning, activated by the phrase "let's think step-by-step", on BIG-Bench tasks. In general, zero-shot CoT Flan-PaLM outperforms zero-shot CoT PaLM without finetuning.
CoT 微調可以解鎖zero-shot 推理,透過“讓我們逐步思考”短語在 BIG-Bench 任務中啟動。一般來說,zero-shot CoT Flan-PaLM 優於沒有微調的zero-shot CoT PaLM。
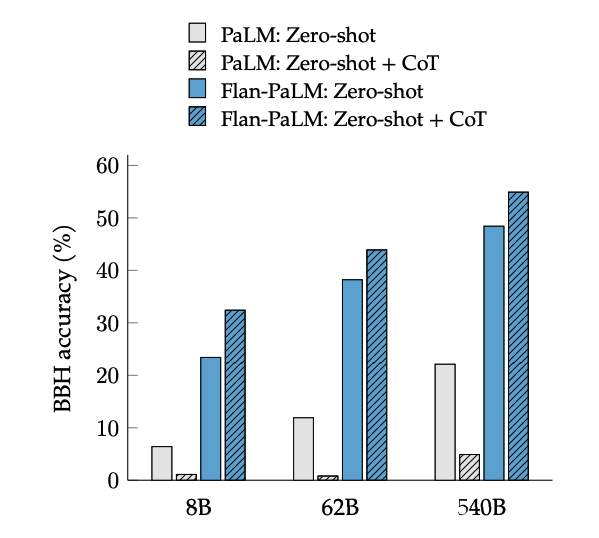
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
Below are some demonstrations of zero-shot CoT for PaLM and Flan-PaLM in unseen tasks.
以下是 PaLM 和 Flan-PaLM 在未知任務中的零樣本 CoT 示範。
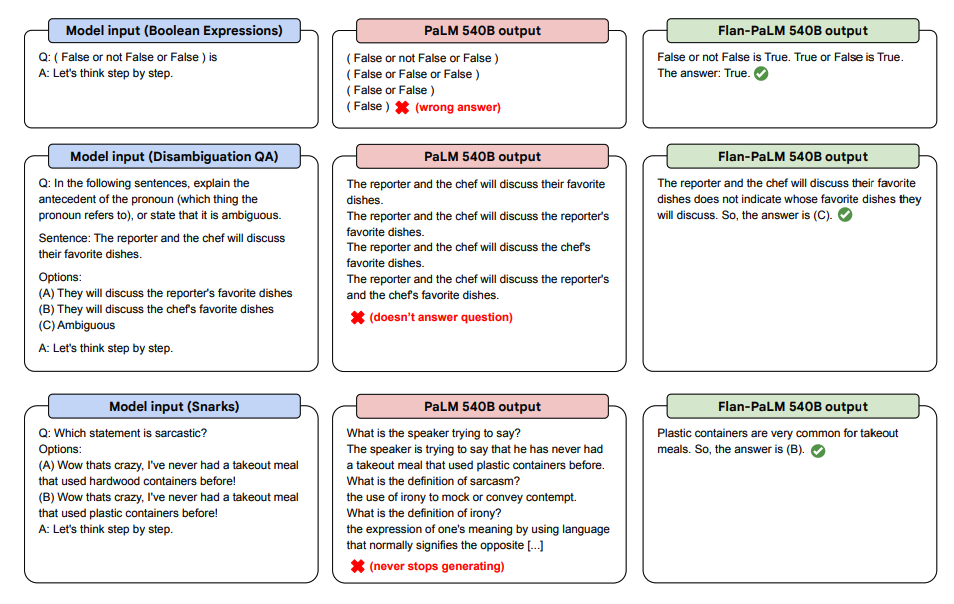
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
Below are more examples for zero-shot prompting. It shows how the PaLM model struggles with repetitions and not replying to instructions in the zero-shot setting where the Flan-PaLM is able to perform well. Few-shot exemplars can mitigate these errors.
以下是更多的zero-shot提示示範。它展示了 PaLM 模型在重複和不回覆zero-shot設定中的指令方面的困難,而 Flan-PaLM 能夠表現良好。少量示範可以緩解這些錯誤。
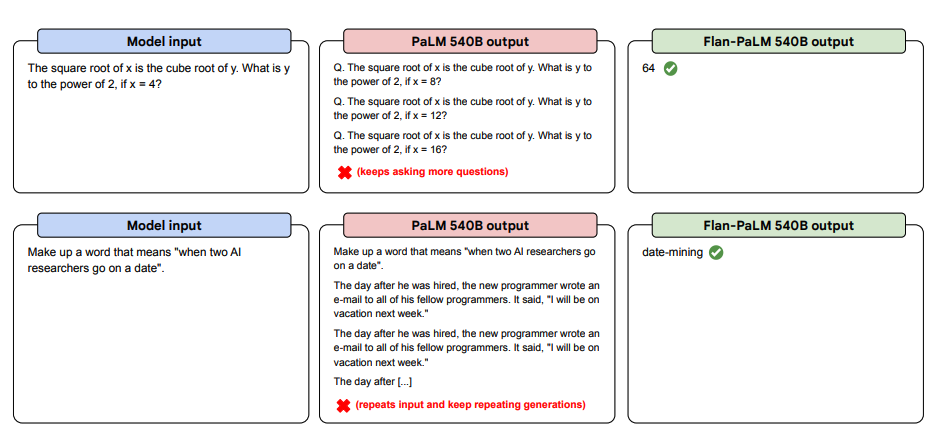
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
Below are some examples demonstrating more zero-shot capabilities of the Flan-PALM model on several different types of challenging open-ended questions:
以下是一些示範,展示了Flan-PALM模型在幾種不同型別的具有挑戰性的開放式問題上的更多zero-shot能力:
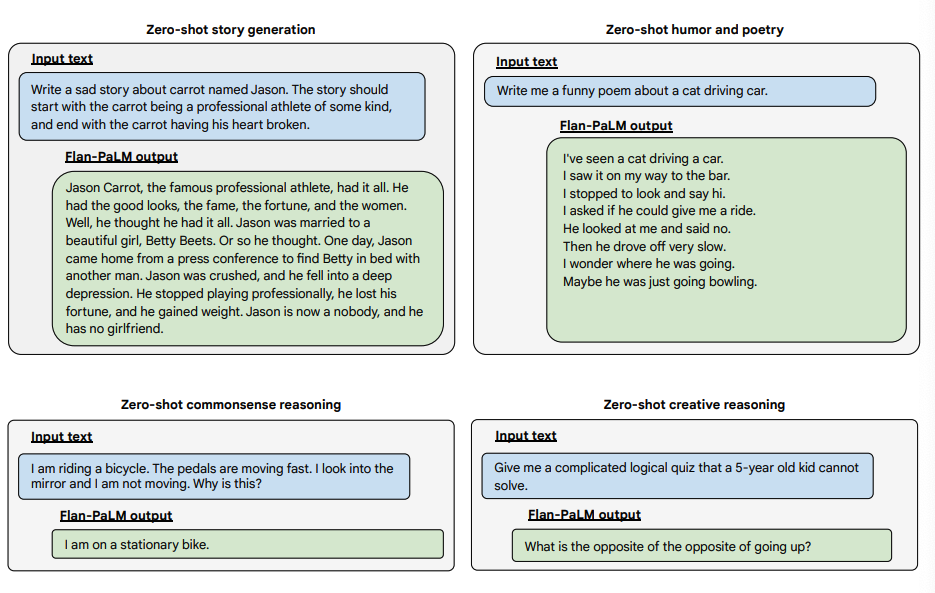
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
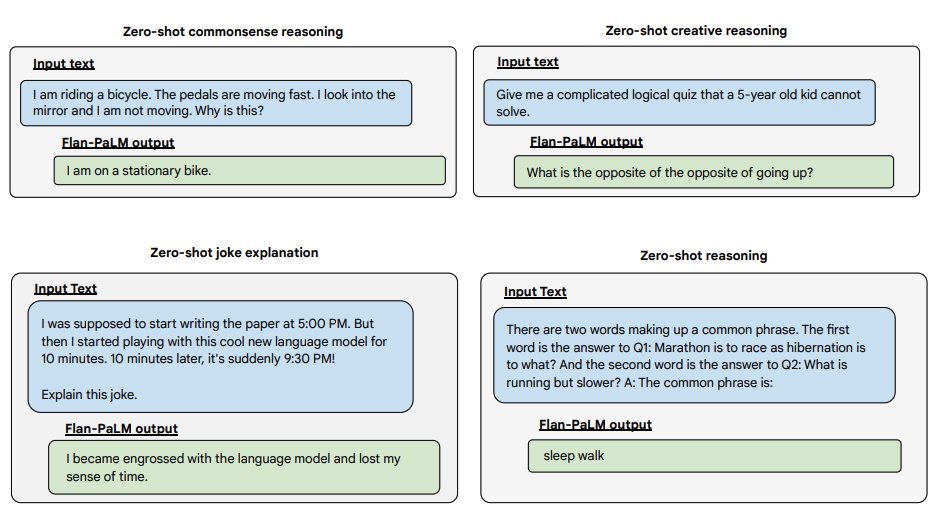
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
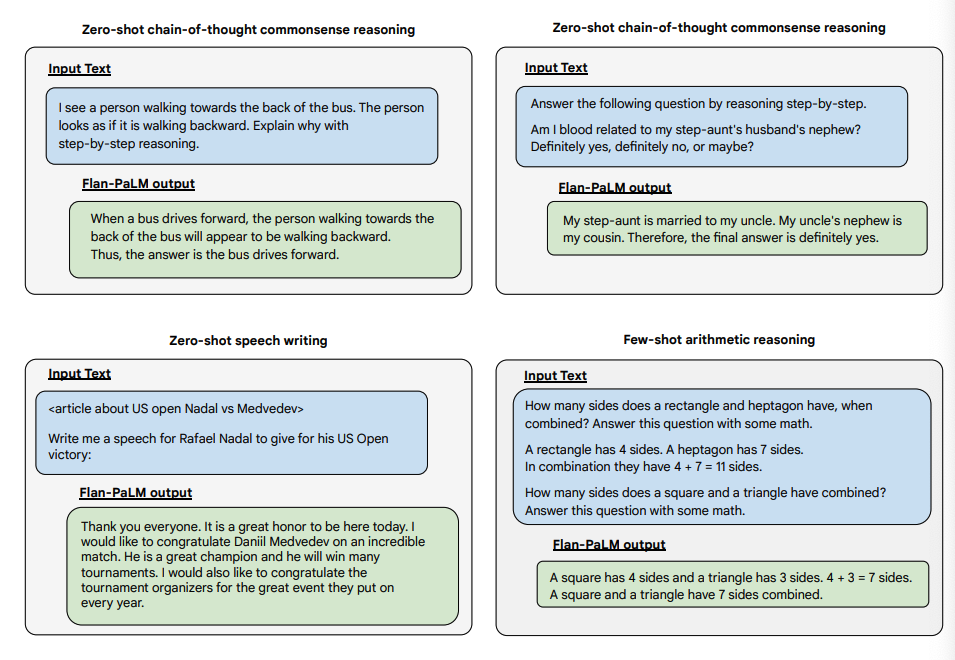
Image Source: Scaling Instruction-Finetuned Language Models (opens in a new tab)
圖片來源:Scaling Instruction-Finetuned Language Models (opens in a new tab)
You can try Flan-T5 models on the Hugging Face Hub (opens in a new tab).
你可以在 Hugging Face Hub 上嘗試 Flan-T5 模型 (opens in a new tab)。